如何让 Hermes Agent 跑本地 Ollama 模型
一篇实用指南:怎么把 Hermes Agent 接到本地 Ollama 模型,安装顺序是什么,setup wizard 里到底该怎么填,以及 Hermes 当前期待的 endpoint 是什么。
如何让 Hermes Agent 跑本地 Ollama 模型
如果你想让 Hermes Agent 不再依赖云 API,Ollama 基本就是最直接的路线。
当前官方集成路径其实很简单:
- 先装好 Hermes
- 再装 Ollama
- pull 一个本地模型
- 运行
hermes setup - 把 Hermes 指到本地 Ollama endpoint
这里最关键的细节是:Hermes 现在期待的是 Ollama 的 OpenAI-compatible endpoint:
http://127.0.0.1:11434/v1
这篇文章就围绕这条当前官方路径来写。
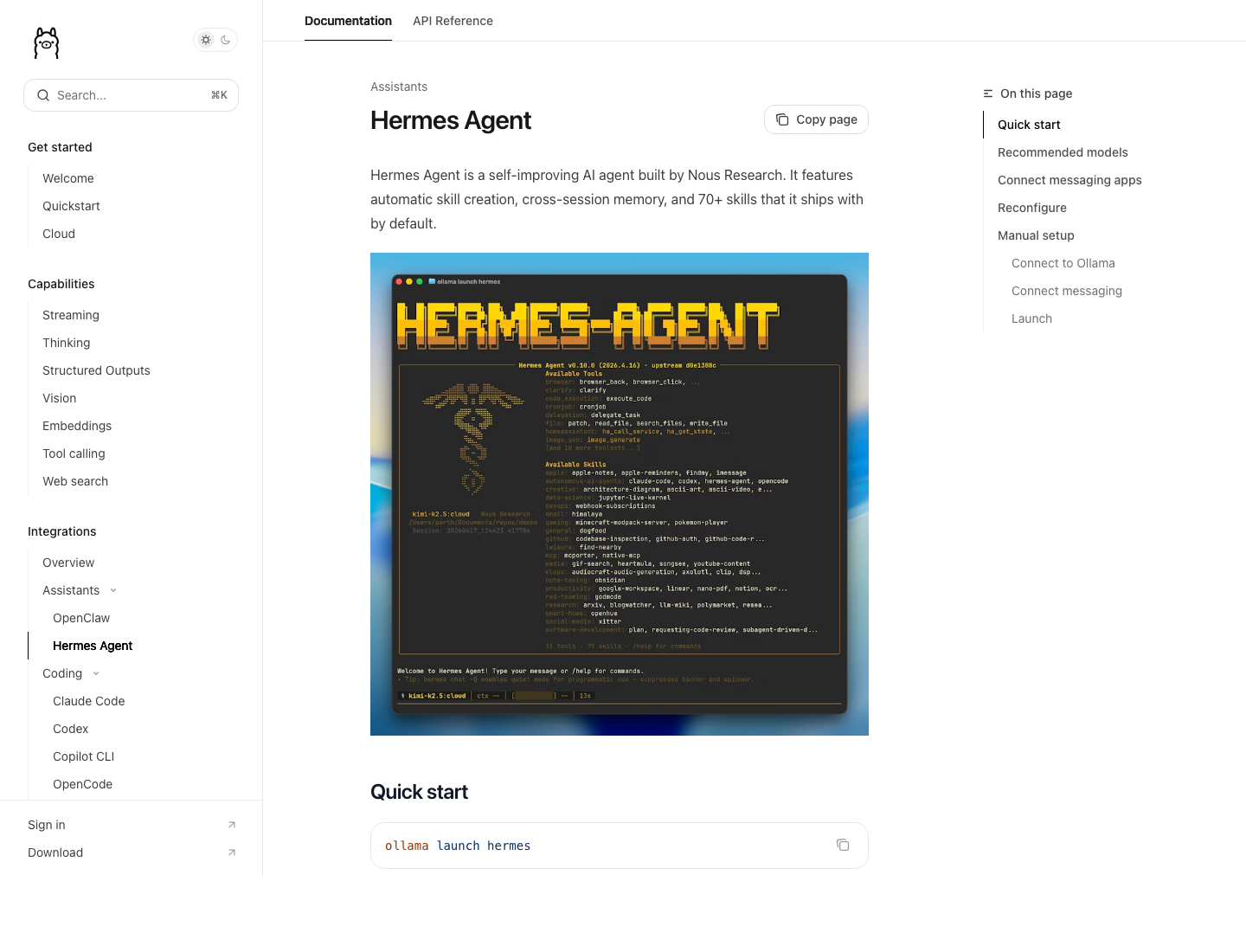
来源:Hermes Agent on Ollama docs
开始前先确认这几件事
在动本地模型之前,先确保:
- Hermes Agent 已经装好
hermes --version能正常跑- Ollama 已安装
- 你的机器内存够支撑你要跑的模型
如果 Hermes 基础安装都还没稳,就不要在本地模型这一步排问题。
第 1 步:安装 Ollama
先从 ollama.com 安装 Ollama。
Linux 和 macOS 常见安装命令是:
curl -fsSL https://ollama.com/install.sh | sh
然后验证:
ollama --version
第 2 步:先 pull 一个模型
Hermes 的 Ollama 集成文档明确建议:在跑 setup wizard 之前,先确保本地已经有模型,因为 Hermes 会自动检测本地可见模型。
例如:
ollama pull qwen3.5
文档里也提到了一些本地模型选项,比如:
gemma4qwen3.5
选模型时别只看名字,要看你机器到底跑不跑得动。能加载但慢到没法用,不算成功部署。
第 3 步:启动 Ollama
如果 Ollama 还没在本地服务模式运行,就启动它:
ollama serve
默认情况下,Ollama 本体地址是:
http://127.0.0.1:11434
而 Hermes 当前对接时用的是 OpenAI-compatible 路径:
http://127.0.0.1:11434/v1
这正是当前官方集成文档里让你填写的 endpoint。
第 4 步:运行 Hermes Setup
现在开始 Hermes 的 setup wizard:
hermes setup
然后按当前官方文档里的流程走:
- 选择
Quick setup - 进入
More providers... - 选择
Custom endpoint (enter URL manually) - 填这个地址:
http://127.0.0.1:11434/v1
- API key 留空
- 让 Hermes 自动检测本地模型
- 确认检测到的模型
- context length 留空,让它自动检测
这就是现在官方给出的集成路径。
Setup Wizard 这一步到底在做什么
根据当前集成文档,Hermes 会通过下面这个地址验证本地 Ollama:
http://127.0.0.1:11434/v1/models
然后把检测到的本地模型列出来,问你要不要用。
这说明两件事:
- Hermes 不是让你一开始就手写复杂配置
- 如果本地模型在这里不可见,setup wizard 就没法顺利完成
第 5 步:跑一个真实会话验证
setup 完成之后,正常启动 Hermes:
hermes
然后先试一个小任务,不要一上来就拿大工作流硬冲。你首先要确认:
- 模型能正常回应
- 延迟你能接受
- 机器负载撑得住
如果后面想切换模型,可以再用:
hermes model
哪些场景适合本地 Hermes
Hermes 跑本地模型,比较适合这些需求:
- 数据尽量留在本机
- 不想持续支付云 API 费用
- 想先把本地工作流搭起来
- 把 Hermes 当成私人、本地的 agent runtime
它比较适合:
- 起草
- 摘要
- 简单自动化
- 个人知识工作流
但如果你想在弱机器上获得接近一线云模型的推理能力,通常不现实。
最常见的 5 个错误
1. Hermes 基础安装没稳就急着上本地模型
如果 hermes 本身还跑不稳,先修安装问题。
2. 没 pull 模型就直接跑 setup
官方文档的思路是:本地已有模型,Hermes 自动检测。
3. endpoint 填错
按当前官方集成路径,Hermes 期待的是:
http://127.0.0.1:11434/v1
4. 选了机器根本撑不住的模型
模型能起,不代表响应速度够用。
5. 以为本地一定适合所有任务
本地的优势是隐私和成本,不代表所有任务质量都自然够。
一个够用的本地 Hermes 基线
如果你只想先把本地路径跑通,可以按这个顺序来:
- 安装 Hermes
- 安装 Ollama
- pull
qwen3.5或其他合适模型 - 运行
hermes setup - 把 endpoint 填成
http://127.0.0.1:11434/v1 - 确认检测到的模型
- 跑一个小任务验证
这已经足够得到一个真正可用的本地 Hermes 会话。
快速检查清单
- 先装好 Hermes
- 安装 Ollama
- pull 一个本地模型
- 启动 Ollama
- 运行
hermes setup - 使用
http://127.0.0.1:11434/v1 - 确认模型已被检测到
- 先拿小任务测试